PPO in Particle Environment
Published:
As we know, reinforcement learning(RL) suffers from large variance and doesn’t have stable learning signals like supervised learning. The learning process appears like a seesaw to me that may make its performances on past experiences worse when learning about new things. I previously wrote a demo to learn to recite the infinite non-repeating decimals $\pi$ sequentially with hidden size 64 and can only recite only up to 1700 digits. The recurrent neural network(RNN) predicts 10 digits at one time and is trained with those 10 digits at each time step. If the network predicts the results correctly, then we move to the next 10 digits. Otherwise, the neural network has 90 percents chance to predict it again after training with the labels and 10 percents to predict from the beginning again. In the test time, RNN recites $\pi$ from the beginning until it outputs the wrong results. Though the training procedure applies supervised learning, it’s also a Markov Decision Process and has something similar to RL. If the network changes its parameters, then the memory passed by the RNN can also vary accordingly, but the changes in memory are not considered in current time step and can influence RNN’s predictions in test time. Though this kind of problems can be alleviated by offline learning and large batch size training, how to balance the reinforcement learning data still remains as one problem.
PPO serves as the basic reinforcement learning algorithm of Open AI. I’d like to interpret PPO in an intuitive ways. The PPO equation is
$L^{CLIP}(\theta)=min(r_t(\theta)\hat{A}_t, clip(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t)$.
Further information about PPO please refer to the paper. Assume $A_t$ is greater than zero, then if we don’t clip the ratio $r_t(\theta)$, the optimisation target may sacrifice its performance on some other states for better performance on some states. However, those states are causal and can’t be treated like the data in supervised learning. For example, if we train using mini-batch and the discount factor is one which means the advantages should be the same ideally, we take the $i_{th}$ and $j_{th}$ entry from this batch. Now if $\pi_{old}(a_i|s_i) = 0.8$, $\pi_{old}(a_j|s_j) = 0.1$ and $\epsilon = 0.2$. Then even though $\pi(a_i|s_i)=0.4$ and $\pi(a_j|s_j)=0.3$ ($r_i + r_j = 3.5$, where $r_i=0.5$ and $r_j=3$.), the loss can improve with respect to the two entries but can lead to totally different trajectory. Thus, if we are optimising them together in an off-line manner, a part of data may destroy the learned policy by a significant amount. PPO limits this kind of tradeoff by clip the ratio, then in the same case $r_i + r_j$ are clipped to 1.2, and the loss comes from $r_j$ doesn’t overwhelm that from $r_i$ again.
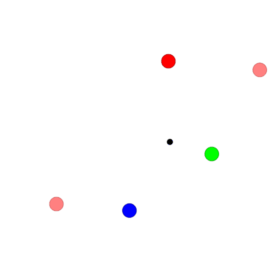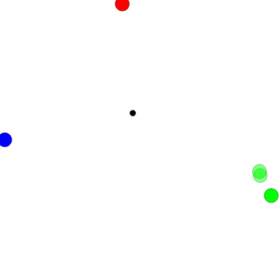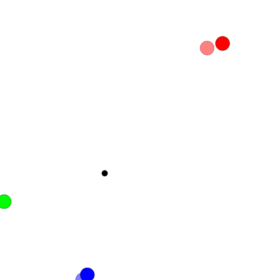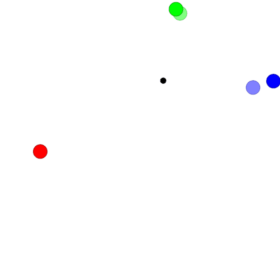
I found one interesting phenomenon when I used the platform multiple_particle_env to do one experiment. The simple scenario is that two particles know about their own goals and target at reaching their goals among the three landmarks. The particles’ colour is the same as their goals. At every time step, each particle’s reward is represented by the negative distance between it and its goal.
Though DDPG has shown its capacity to solve this kind of problems, we try to solve them using traditional policy gradients architectures. I implemented it with vanilla policy gradients at first but find two agents go to the same places which are not any landmarks without communications. After analysis, their final positions seem to be near the centre of three landmarks, which is denoted as one black circle. The agents can’t learn from differences of different goals because agents with different goals go to nearly the same places. The performance of that one is displayed in the following. Further information about PPO please refer to the paper. Assume $A_t$ is greater than zero, then if we don’t clip the ratio $r_t(\theta)$, the optimisation target may sacrifice its performance on some other states for better performance on some states. However, those states are causal and can’t be treated like the data in supervised learning. For example, if we train using mini-batch and the discount factor is one which means the advantages should be the same ideally, we take the $i_{th}$ and $j_{th}$ entry from this batch. Now if $\pi_{old}(a_i|s_i) = 0.8$, $\pi_{old}(a_j|s_j) = 0.1$ and $\epsilon = 0.2$. Then even though $\pi(a_i|s_i)=0.4$ and $\pi(a_j|s_j)=0.3$ ($r_i + r_j = 3.5$, where $r_i=0.5$ and $r_j=3$.), the loss improve with respect to the two entries but the new policy can lead to totally different trajectory. Thus, if we are optimising them together in an off-line manner, a part of data may destroy the academic policy by a significant amount. PPO limits this kind of tradeoff by clip the ratio, then $r_j$ here is clipped to 1.2 while $r_i$ is still 0.5. The loss comes from $r_j$ doesn’t overwhelm $r_i$ with the clipped ratio.
I found one interesting phenomenon when I used the platform multiple_particle_env to do one experiment. The simple scenario is that two particles know about their own goals and target at reaching their goals among the three landmarks. The particles’ colour is the same as their goals. At every time step, each particle’s reward is represented by the negative distance between it and its goal.
Though DDPG has shown its capacity to solve this kind of problems, we try to solve them using traditional policy gradients architectures. I implemented it with vanilla policy gradients at first but find two agents go to the same places which are not any landmarks without communications. After analysis, their final positions seem to be near the centre of three landmarks, which is denoted as one black circle. The agents can’t learn from differences of different goals because agents with different goals go to nearly the same places. The performance of that one is displayed in the following.

The agent can’t find better learning signals from the data, so it compromises to try to find the center of three landmarks to avoid more severe punishments. It appears like a bug in my program. However, when I and my colleague use PPO instead, the particles can reach their goals exactly. The comparison provides one indirect proof that the vanilla policy gradients may meet the tradeoff problems mentioned above. The performance of PPO is shown in the following.