
Learn Shared Dynamics with Meta-World Models
Published:
We often consider the features from the appearance. Sometimes, we also try to learn the features correlated to the context, like word embeddings. Words with similar properties can share some similarities in the word embedding space. Now, consider reinforcement learning(RL) environment states from this aspect: If two world environments hold different state space $\mathcal{S}_1$ and $\mathcal{S}_2$, but they have the same action space $\mathcal{A}$ and the agent interacts with the environments in the same way physically. We call the two worlds to have the same dynamics.
For example, you and your reflection in the mirror have the same dynamics, but the observations are reversed horizontally. However, when you consider your reflection in the mirror is yourself, you started to unify the representations of you and it. The example may also be one illustration of the mirror test which shows the existence of self-consciousness.
To explore the same process using machine learning, we proposed to use the shared dynamics to learn a meta-world model. The meta-world model is based on the world model architectures. The world model consists of Vision($\mathcal{V}$) model and Memory($\mathcal{M}$) model. We choose the V model as VAE, and the M model as LSTM in our architecture. Meta-World aims to learn the shared dynamics among multiple worlds so that one M model is shared across different world environments while each world keeps one individual V model. The training loss comes from the reconstruction loss of VAE and the prediction loss of LSTM. In correspondence, the training procedure is divided into reconstruction phase $\mathcal{R}$ and prediction phase $\mathcal{P}$. In the $\mathcal{R}$ phase, we train VAE using reconstruction loss. In the $\mathcal{P}$ phase, we train both VAE and LSTM using prediction loss. The reason why we don’t train the models jointly is that the conflicts between the two kinds of losses can lead the meta-world model to a local minimum with poor performances.
The two training phases can be understood as:
- $\mathcal{P}$ phase destroys the reconstruction ability of $\mathcal{V}$ models to be compatible with the shared dynamics;
- $\mathcal{R}$ phase recovers the reconstruction ability of $\mathcal{V}$.
Two phases alternate until they reach the balance.
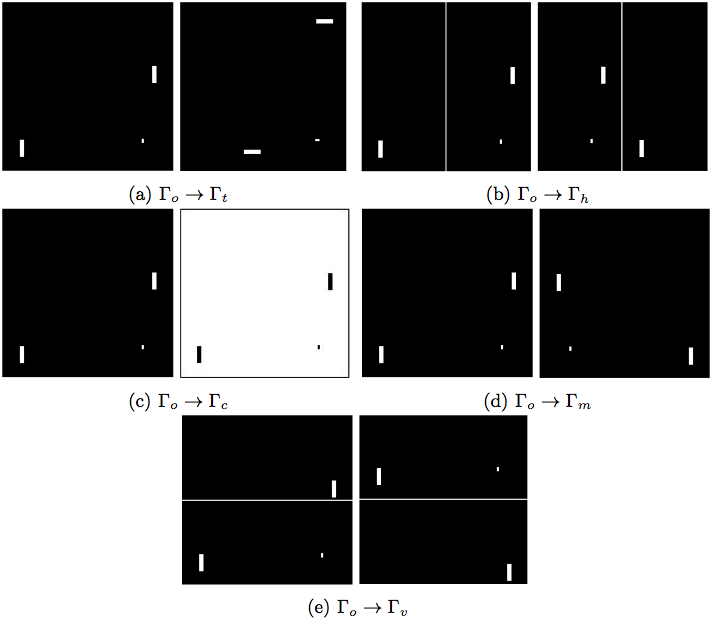
Our experiments are carried on the variants of the Atari Pong environment. Pong environment is preprocessed into binary images at first. Then we have five kinds of variants of it which is shown in Fig.1. $\Gamma_o$ is the original world and five variants are $\Gamma_t$, $\Gamma_h$, $\Gamma_v$, $\Gamma_c$, $\Gamma_m$. $\Gamma_t$ is the transpose of the original world; $\Gamma_v$ divided $\Gamma_o$ into two parts vertically and swap them and $\Gamma_h$ is obtained similarly but horizontally; $\Gamma_c$ changes the colour of $\Gamma_o$; $\Gamma_m$ is $\Gamma_o$’s mirror world. All those worlds have different state space, but with the same action space and the physical meanings of actions are the same.
The problem appears that how can we know we have learned the shared dynamics because the network capacity allows it to learn many dynamics simultaneously. We validate it indirectly by observing whether the representations of corresponding states from different worlds are unified. If they’re similar, they share the same representations, and the dynamic changes between adjacent states are also the same. For the variational inference in VAE, the latent vectors are generated from distribution and KL divergence between two distributions with low variance can be very high. Thus, we choose not to compare the latent vector $z$ of VAE directly. We can decode the $z$ encoded by one world’s V model using another world’s V model and see whether the output is the corresponding state. If it is, we regard it as the symbol that we learn the shared dynamics, and it also leads to the fact that the shared dynamics can unify the representations.
In our most experiments, we choose $\Gamma_o$ and one world from {$\Gamma_t$, $\Gamma_h$, $\Gamma_v$, $\Gamma_c$, $\Gamma_m$} to train the meta-world. The validation results are listed below.

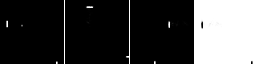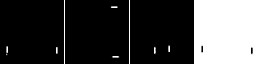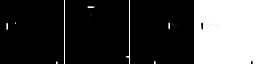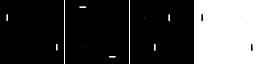
In summary, what we only do is let the agent try to find one shared dynamics to associate itself and ‘itself’ in another world, then it’s able to pass the mirror test. We also try to train multiple worlds together and improve the success probability of training multiple worlds. As a result, we also find something interesting which may be updated later or delivered in a new post.